没有云端支持,直接在我的计算机上运行AI……Ollama通过苹果专用技术重新设计
与前一版本相比,处理速度提高最多达11倍……也正式支持与编码AI代理的联动
需要32GB以上内存的Mac……目前主要支持阿里巴巴Qwen模型

什么是Ollama
使用AI的方法主要有两种。一种是通过互联网访问服务器,就像ChatGPT一样;另一种是直接在自己的计算机上下载和运行AI模型。这后一种方式被称为“本地AI”。
本地AI的优点是个人信息不会传输到外部,而且即使没有互联网也可以使用。它在需要高度安全的企业环境和处理敏感信息的工作中尤其受到关注。其问题在于安装和运行较为复杂。一般人,甚至开发者都觉得这是一块难啃的骨头。
Ollama正是为了解决这种不便而制作的程序。它允许用户无需复杂设置,只需一行命令就能将AI模型下载到自己的计算机上并立即运行。因此,它成为本地AI领域最广泛使用的工具之一。3月30日发布的0.19版本将其性能提升到了一个新的高度。
速度变了…从数值看
本次更新的核心是与苹果的结合。Ollama 0.19设计用于在苹果自主开发的机器学习专用模块“MLX”上运行。由于充分发挥了苹果芯片特有的内存结构,速度显著提升。
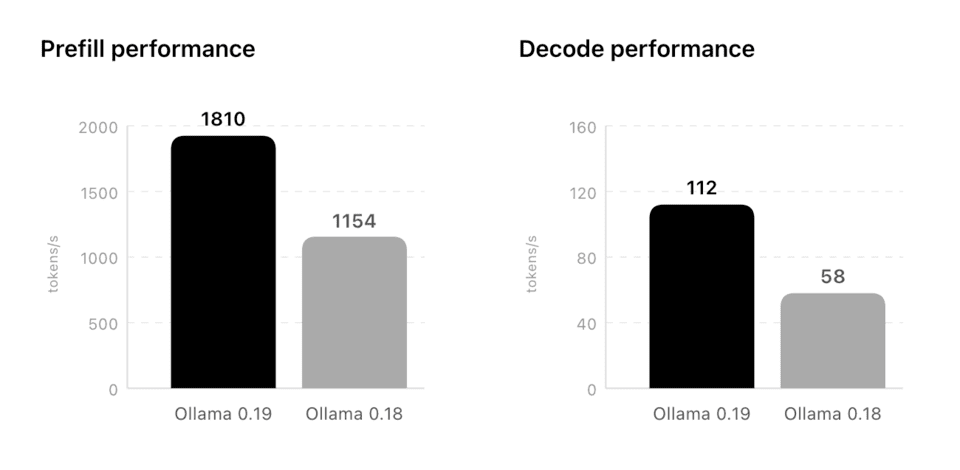
上月29日根据阿里巴巴的AI模型进行了测试,这验证了上述说法。AI读取和理解长文章的速度,即“预填”性能比之前版本快约11倍。
以前每秒能处理154个单元,而新版本每秒可以处理1,810个。生成并输出答案的速度比以前提升了约93%。从每秒58个增加到112个。
在最新的M5、M5 Pro和M5 Max芯片上,首次利用芯片内置的专用运算单元进一步提升了这些速度指标。
与编码AI的连接
本次更新中不能忽视的变化还有与编码专用AI代理的官方结合,目标包括Claude Code、OpenCode、Codex等工具。这些工具与开发者直接协作,帮助编写和修改代码。从现在开始,用户可以在自己的计算机上运行这些工具。
实现上述功能的技术之一是缓存改善。缓存是预先存储经常使用的信息的空间。Ollama 0.19使缓存可以在会话中重复使用。在使用像Claude Code这样常常重复相同指令的工具时,内存使用量减少,响应速度加快。新增的功能还包括自动在重要提示点处进行中间储存。即使部分对话消失,也无需从头再处理。
此次还新增支持NVIDIA的NVFP4格式。这项技术在保持AI模型准确度的同时,减少内存使用量和存储空间。可在个人计算机上使用与云服务提供商在实际运行环境中使用相同的格式,这一点值得注意。
并非人人可用
与期待相匹配的还有现实的制约条件。要充分利用本次预览版本,需要32GB以上的Mac整合内存。整合内存是由CPU和GPU共同使用的共享内存,是苹果硅芯Mac的结构性特征。也就是说,基础型MacBook Air(16GB)无法运行本次主推的模型。
目前仅支持阿里巴巴的Qwen3.5-35B-A3B模型。Ollama表示未来将支持更多模型,但尚未公布具体时间。用户自行创建定制模型的导入方法也暂时有限。
在我的计算机上运行AI意味着信息不会泄露到外部服务器。此次更新的本质尝试是同时抓住速度和安全性。为了让本地AI不只是部分开发者的实验,而成为实用的选择,Ollama 0.19将记录为加速这一进程的更新。