OpenAI于2025年3月25日将最新的AI模型GPT-4o的图像生成功能直接整合到ChatGPT中,展示了比以往更自然和精细的视觉创作工具。此次更新取代了现有的DALL·E基础系统,设计旨在使AI能够理解用户的句子并根据对话上下文生成图像。
如今,ChatGPT用户无需额外工具即可在聊天窗口直接创建图像。Plus、Pro、Team和Free套餐的用户均可使用该功能,免费用户每天最多可生成三张图像。付费订阅用户可以无限制地创建图像,企业和教育用户也将很快能够使用该功能。
OpenAI计划在未来几周内为开发者发布API,预计通过该API,外部应用和服务也将能够利用GPT-4o的图像生成能力。
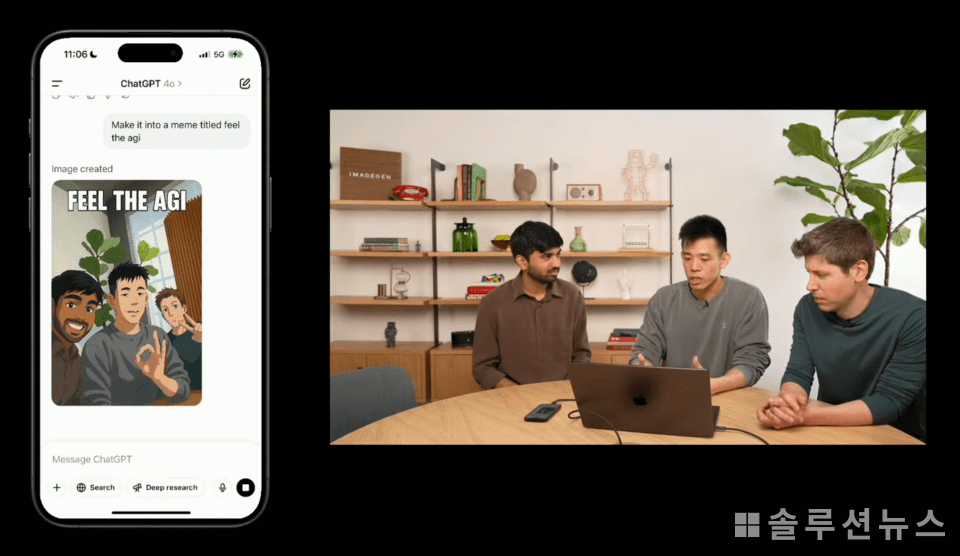
GPT-4o具备同时识别和布局最多20个对象的高级处理能力。例如,它能够自然地构造出如“正在吃爆米花看电影的狗”这样复杂的场景。手、脸、文本等难以表达的元素也能够精细地渲染,图像生成速度平均为30秒至1分钟内。
在记者亲自使用OpenAI的ChatGPT 4o模型进行图像生成时,其表现令人印象深刻。当输入“制作一幅吃着爆米花看电影的狗的图像”这一句子后,仅数十秒便生成了符合该场面的图像。狗坐在沙发上拿着爆米花看屏幕的样子,构图和表情都被精致地表现出来,手和脸等难以呈现的要素也被自然渲染。
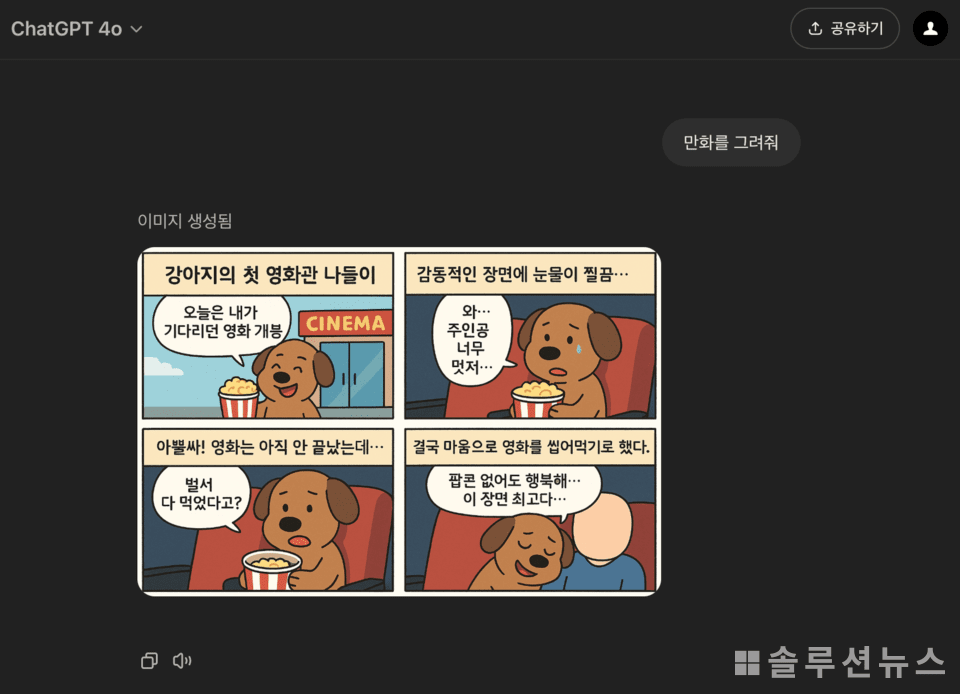
之后,基于该图像添加对话气泡和背景,制作出四格漫画的结果显示,图像质量和风格自然衔接,没有被破坏。仅通过文本输入即可制作到漫画层次的图像,这一创意带来了对传统内容制作方式的新鲜冲击。
用户还可以在创建图像之前精细指定颜色(十六进制代码)、背景(包括透明)和比例,使用自然语言自由指示所需的风格和细节。生成的图像会保持对话的上下文,并且可以在相同风格中重复生成或修改请求。
OpenAI强调,这种方式不仅是简单的AI功能,而是发展为结合创作与交流的“生成型界面”。
此次GPT-4o整合使得DALL·E从基本图像生成工具退居辅助角色。然而,OpenAI保留了以艺术风格或实验图像为强项的DALL·E,并让用户在需要时自由切换这两种模型。用户可以为实用或商业工作选择GPT-4o,而为情感或艺术工作选择DALL·E。
通过此措施,用户在功能与创造性之间能得到更广泛的选择权。这一架构使得根据不同职业和目的使用生成型AI工具成为可能。
OpenAI还将此次图像生成功能与其视频生成模型“Sora”进行联动。Sora是一种AI视频生成引擎,能够以文本、图像、视频为输入,制作1080p分辨率的20秒视频。
用户可以情节板格式输入场景设置,能够编辑现有视频或自然连接两个视频。目前,Sora提供给Plus及Pro套餐订阅者,Pro用户还可以下载无水印的高清晰度视频。

Sora被用于广告、短篇视频、动画等内容制作领域,一些好莱坞制作人目前也在进行测试。
OpenAI通过整合GPT-4o与Sora,生成型AI正在构建一个在文本、图像、视频等各个领域运作的“多模态环境”。
此次更新显示,图像生成技术不再只是技术上的玩物,而是成为实际创作和交流的核心工具。OpenAI表示:“如果用户愿意,我们的目标是更广泛地保证创意自由,同时根据社会标准进行适当控制。”所有生成的图像均包含记录来源的C2PA元数据,以加强追踪和透明度。