谷歌将人工智能(AI)的概念扩展到另一个层次。迄今为止,AI主要在文字和图像领域活动,如撰写文章或绘制图画。然而,谷歌于本月7日(当地时间)首次公开的“Gemini 2.5 计算机使用模型”超越了简单生成信息的层级,可以直接操作实际的电脑屏幕。

谷歌依托其AI平台“Gemini 2.5 Pro”的视觉识别和逻辑推理能力开发了这一模型。
该模型能够理解用户下达的指令,自主进行网页或应用程序界面的按钮点击或文字输入。例如,它可以完成网站的会员注册表单、在电子表格中输入数据,甚至预订系统中的安排调度等任务。
谷歌介绍说,该模型是“在Web和移动环境中比现有AI更精确和响应更快速的新型AI”。开发者可以通过“Google AI Studio”和“Vertex AI”平台使用这项功能。
传统AI主要通过‘API(应用程序接口)’方式进行数据交换。然而,大多数数字工作的许多环节仍需人眼观看并亲自操作。例如,在网站的输入栏中填写信息并提交等动作是属于需人力完成的典型任务。
‘Gemini 2.5 计算机使用模型’自动执行这一流程。模型在接受到用户的请求、屏幕截图及前一动作记录后,分析出“需点击哪个按钮”、“需输入怎样的文本”。AI的判断被转换为“点击”、“输入”、“滚动”等指令并在实际屏幕上执行。
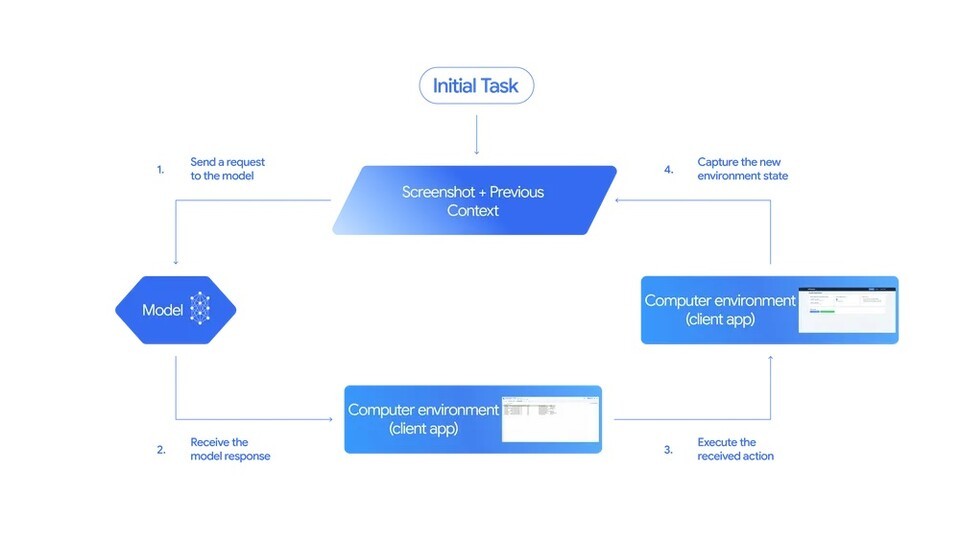
任务执行后,新屏幕被再次传回给模型,模型重复这一过程,直至完成目标任务。谷歌称其为“AI观看屏幕并重复行为直至完成工作的循环结构”。迄今AI主要是通过语言进行工作,而这一模型更像是“拥有眼睛和手的AI”概念。
谷歌称,Gemini 2.5 计算机使用模型在评估网络和移动操作能力的各种指标中均超越了竞争对手。在主流的性能评价中如“Online-Mind2Web”、“WebVoyager”和“AndroidWorld”中均居于上位圈。
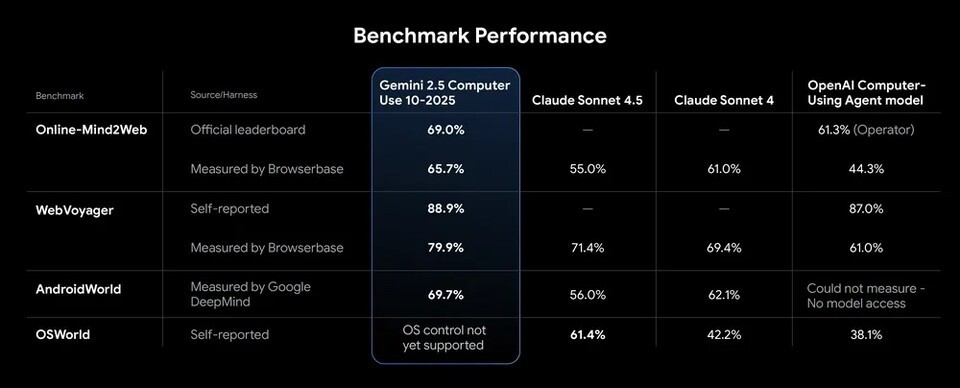
特别是在测量网页浏览器操作性能的“Browserbase”测试中,该模型表现出超过70%的准确率和约225秒的延迟时间,属行业顶尖水平。即在执行相同任务时,能更快更精确地操控界面。谷歌解释称“浏览器控制质量最高且延迟时间最低的模型”。
因AI能直接操作电脑,确保其安全性和稳定性成为核心议题。谷歌在模型设计阶段就考虑了这一问题,内置了多重安全措施。
首先引入“每步安全服务”的应用,以提前评估执行前每一行动的风险性,判断该AI执行的操作是否可能影响系统或构成安全威胁,以进行封阻。
此外,开发者可以通过“系统指令”控制功能限制AI自动执行高风险活动,例如支付、安全设置更改和个人信息访问等。必要时可能需用户确认才能执行命令。
同时,谷歌为开发人员提供安全相关的指导方针,确保遵循认证程序和数据保护原则。公司表示“AI被设计为不会在Web环境中点击恶意链接或未经许可更改系统设置”,并且“所有开发者在发布任何实际服务前必须验证其安全性”。
Gemini 2.5 计算机使用模型已在谷歌内部系统及外部合作公司中试验性使用。谷歌的支付平台开发团队将模型应用于UI测试中,将过去测试失败比例减少了约25%。过去修复错误可能需几天,而AI通过自主分析屏幕并采取措施,改进率提升了超过60%。
外部合作伙伴基于消息的AI助手服务“Poke.com”评价称:“工作速度比竞争对手快50%;准确性大幅提升。”自动化代理公司“Autotab”同样表示“在复杂数据收集环境中,模型表现提升了18%。”
谷歌表示,即日起,以公开预览的形式提供Gemini 2.5 计算机使用模型。开发者可以在“Google AI Studio”和“Vertex AI”中直接测试该功能,并通过“Browserbase”提供的演示环境体验AI真实点击网页和输入过程。
谷歌指出:“AI从仅仅理解语言阶段,已步入实现操作实际界面、代替人力工作的阶段。”未来,谷歌计划将此技术拓展至业务自动化、客户服务和测试自动化等多个产业领域。
AI不仅仅是帮助者,更像是直接工作的同事。