政府首次在生成性人工智能的开发和应用过程中,提出了具体的标准,以便在处理个人信息时更安全有效。
8月6日,个人信息保护委员会在“生成性人工智能与隐私”公开研讨会上发布了《生成性人工智能(AI)开发与应用的个人信息处理指南》。该指南重点是通过为生成性AI的整个过程提供个人信息保护法的应用标准,旨在消除实务现场的不确定性。
指南将生成性AI的生命周期分为五个阶段:目标设定、战略规划、学习与开发、系统应用与管理、治理结构建立,并在每个阶段系统整理了法律注意事项和安全措施。例如,在目标设定阶段,需明确学习目标,并根据个人信息的种类和来源来确保法律处理基础。在战略规划阶段,根据AI模型的使用方式分析风险并制定应对策略。
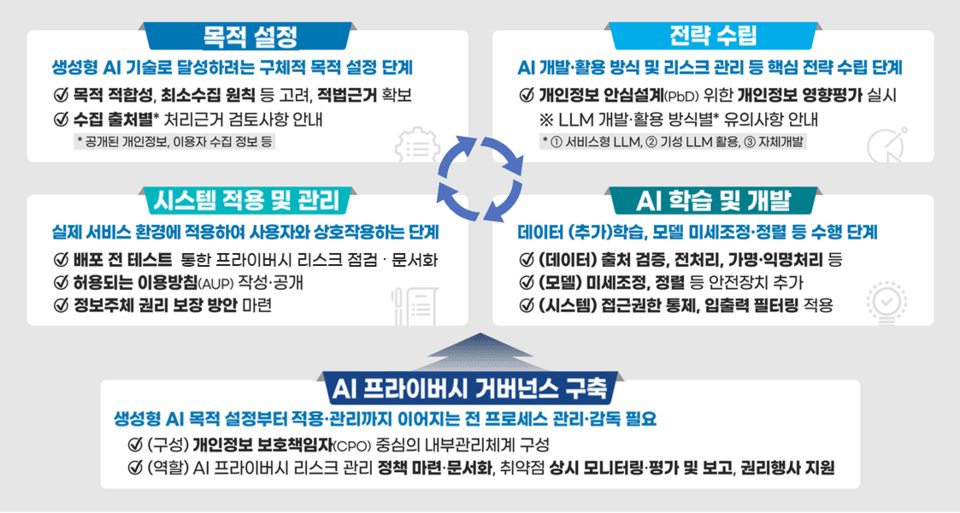
此外,在学习与开发阶段,详细指导了为减少数据污染(data poisoning)、越狱(jailbreak)等风险因素而需采取的技术和管理措施。对于新出现的搜索型和记忆型AI代理,建议引入控制装置以防止非法信息使用和用户画像。
指南中最重要的一部分是“可以用何种目的和如何处理哪些个人信息”的标准。特别指出,与传统业务系统不同,生成性AI可能在学习、验证、运营的多个阶段处理个人信息,并且对目的外使用的解释比较复杂。因此,个人信息委员会将用于生成性AI学习的数据分为从互联网上收集的“公开数据”和企业或机构持有的“用户数据”,并分别提供合法性标准。
首先,根据个人信息保护法第15条第1款第6项,若满足“正当利益”要求,互联网发布的公开数据可以用于学习。然而,在这种情况下,还需满足以下条件:权利侵犯可能性低,数据属于公共关注,信息主体可以轻易请求删除。
相比之下,企业要重新利用从客户等收集到的用户信息用于AI学习,需要根据原始收集目的相关性进行以下判断:在原目的内使用、额外使用、新的独立收集。这时需综合考虑目的变更的必要性、可预见性、信息主体的利益侵害与否、保护措施水平等。指南以企业实际应用案例为例,指引各类判断方向。


指南的最大特点是基于案例的法律解释提高了实效性。个人信息委员会考虑到仅靠现有法规解释难以解决生成性AI开发现场复杂情况的问题,进行了法律问题类型化。
例如,根据生成性AI开发和应用方式的不同,如服务型LLM(例如 ChatGPT API 关联)、现成LLM 利用(例如 Llama 开源模型附加学习)及自我开发(例如 轻量级模型 SLM 开发),个人信息处理风险和法律责任的范围可能会有所不同,并针对这些方式提供相应的保护措施和法律解释标准。
以医疗机构通过企业许可(Enterprise API)自动撰写医疗记录的案例为例,解释了为了加强隐私保护水平而选择许可证的标准。此外,若在模型开发后发现问题,开发者应迅速通报并重新发布改进模型,同时建议用户定期应用补丁。
指南还具体阐述了在人工智能发布后的信息主体保护措施。若因技术局限而限制了信息访问、修改、删除等传统权利的行使,建议清晰告知原因,并通过过滤等替代措施进行补充。
在发布前的阶段,建议通过文件化AI结果的准确性、数据暴露可能性、对规避尝试的抵抗性等来检查风险。

指南强调了个人信息保护责任人(CPO)在生成性AI开发全程中将个人信息保护内置化的重要角色。建议CPO从策划阶段即介入开发全过程,制定信息保护战略,进行个人信息影响评估和红队测试等,持续检查风险。
个人信息委员会表示,有必要在企业内加强治理体系,以便隐私与创新共存,并建立相关部门间的反馈机制。
个人信息保护委员会主席高学秀表示,这一指南将成为生成性人工智能开发和使用过程中的法律不确定性的解决方案,并成为系统性反映个人信息保护观点的契机。他还表示,将继续致力于制定政策基础,以便“隐私”和“创新”能够并存。
指南将依据未来技术发展和国内外个人信息保护政策变化而持续更新。目前,正在准备生成人工智能的企业、机构、初创公司等可以利用这份指南提升自律合规能力并进行实务应用。